Product analytics tools like Amplitude and Mixpanel have been around for over a decade, and they pre-date the modern data stack that is becoming common now. There’s now a disconnect between the world these analytics tools were built for and the reality of how teams work with enterprise data today. This leads to an important question: how should product analytics evolve to fit into the modern data stack?
To answer that, let’s start by addressing a fundamental question: What is the modern data stack?
The modern data stack
As it relates to analytics, we’ll define the modern data stack by the following characteristics:
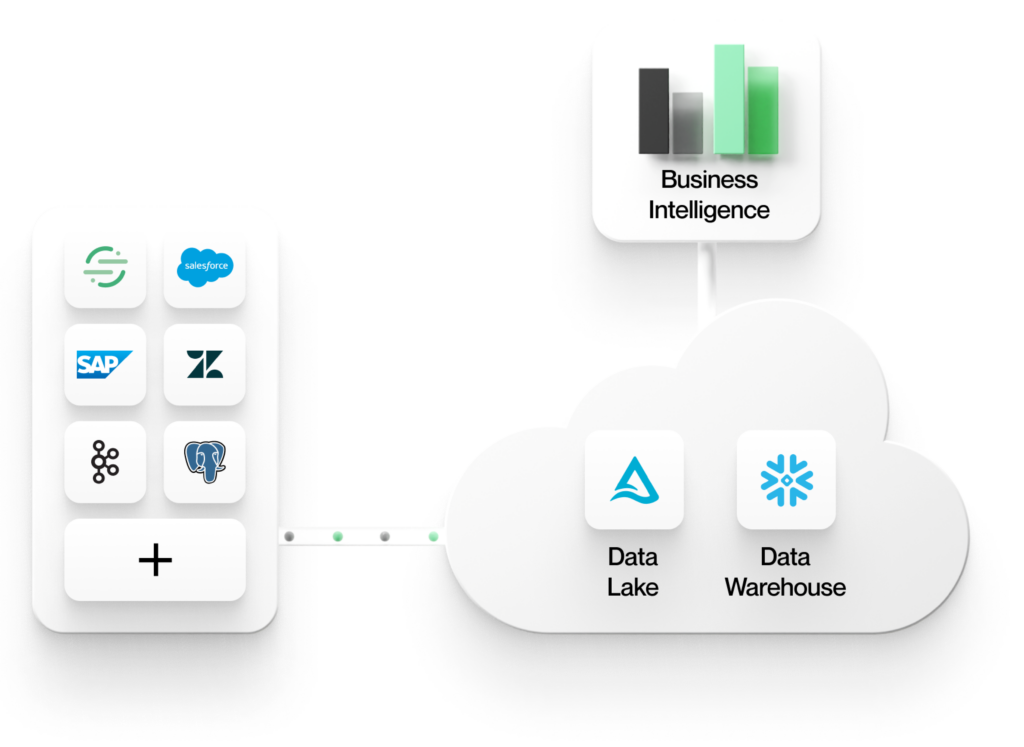
1. All data comes to a common central enterprise data store in the cloud
This store could be a data lake built on an object store such as AWS S3, or it could be a data warehouse such as Snowflake. Whether using a lakehouse or warehouse architecture, enterprises are standardizing on having all data reside in central stores. A common central store offers advantages in terms of consistency, security, governance, and manageability.
2. Analytics tools work directly off data in these stores
Analytics tools in the modern data stack, such as those for Business Intelligence (BI) or AI/ML, don’t need to ETL the data out into other data silos. This guarantees a single source of truth for your data and provides consistent analytic insights across your enterprise. By using open formats in the lake or warehouse, your data becomes accessible to any tool, so you can avoid vendor lock-in. Working directly inside a central store also makes it easier to learn from your data and act on it. All the context you need is together in one place, instead of divided across multiple silos.
The state of product analytics
In contrast to the central store used by modern data systems, most product analytics tools available today are siloed, proprietary, walled systems.
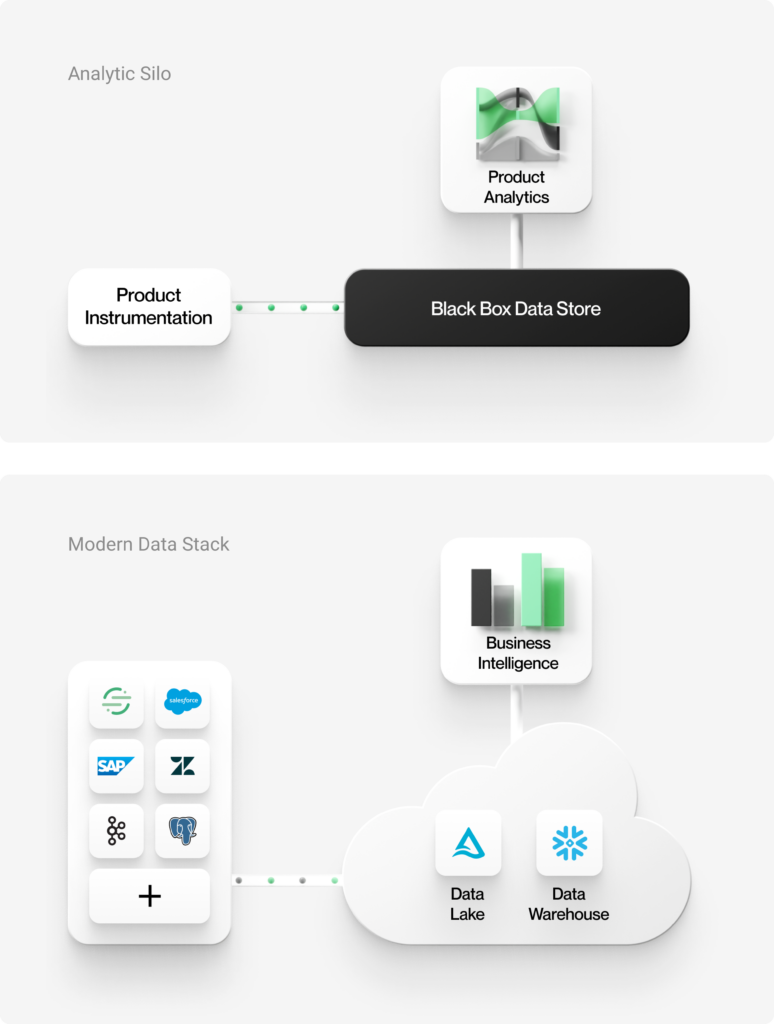
Siloed Data
Typically, product analytics tools work on siloed data. They have integrated product instrumentation libraries that collect and hold data in black box stores within a closed platform. Even if you use a decoupled third-party instrumentation library, to use an analytics tool, your data will have to be shipped to that tool’s black box stores.
Because these product analytics tools rely on siloes, they can only work with a subset of your data, disconnected from the vast majority of enterprise data in your central store. At best, you can bring in a small set of properties from an enterprise data warehouse or data lake using “reverse ETL” tools. Unfortunately, these will be brought in as simple single-value properties and have to be forced into a pre-canned data model.
As a result of this siloed approach, it’s difficult to tie insights from product usage data to the broader business impact. These systems can only perform single-channel analyses, lacking context from other business systems such as Sales, Support, Voice of Customer, and Finance.
Fragmented Analysis
This siloed architecture results in fragmented analytics. Users get analytics limited to in-product usage through these traditional product analytics tools. When they want more detailed insights into customer behavior outside the product, they have to call upon their data engineering and BI teams to build custom reports. Running this analysis can take weeks. Analysts have to ETL data out of the black box stores, write complex SQL queries, and adapt BI tools that are not geared for these kinds of analyses.
Not only is this complex and costly to do, but you now have analytics residing in two separate systems with no ability to share context or seamlessly move back and forth between them. Often, data pipelines aren’t connected, requiring analysts to work with snapshots (one-off custom reports). Having multiple silos of data is a massive TCO problem for enterprises.
There are also security and privacy concerns. It’s becoming increasingly important for customer data to remain within the confines of enterprise-controlled stores instead of being held elsewhere in potentially insecure and non-compliant environments.
Product analytics in the modern data stack
Now, let’s see what product analytics should look like when built upon a modern data stack.
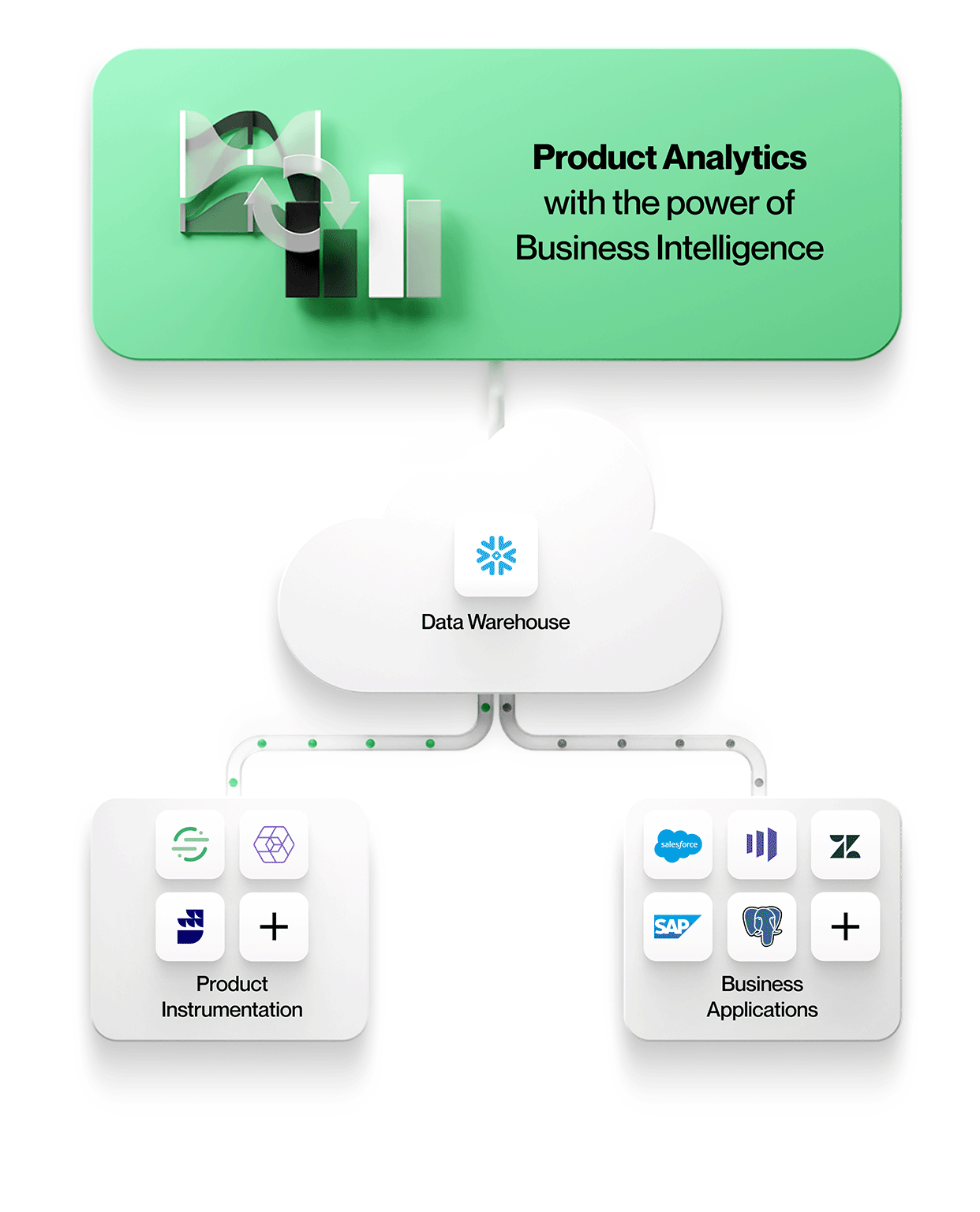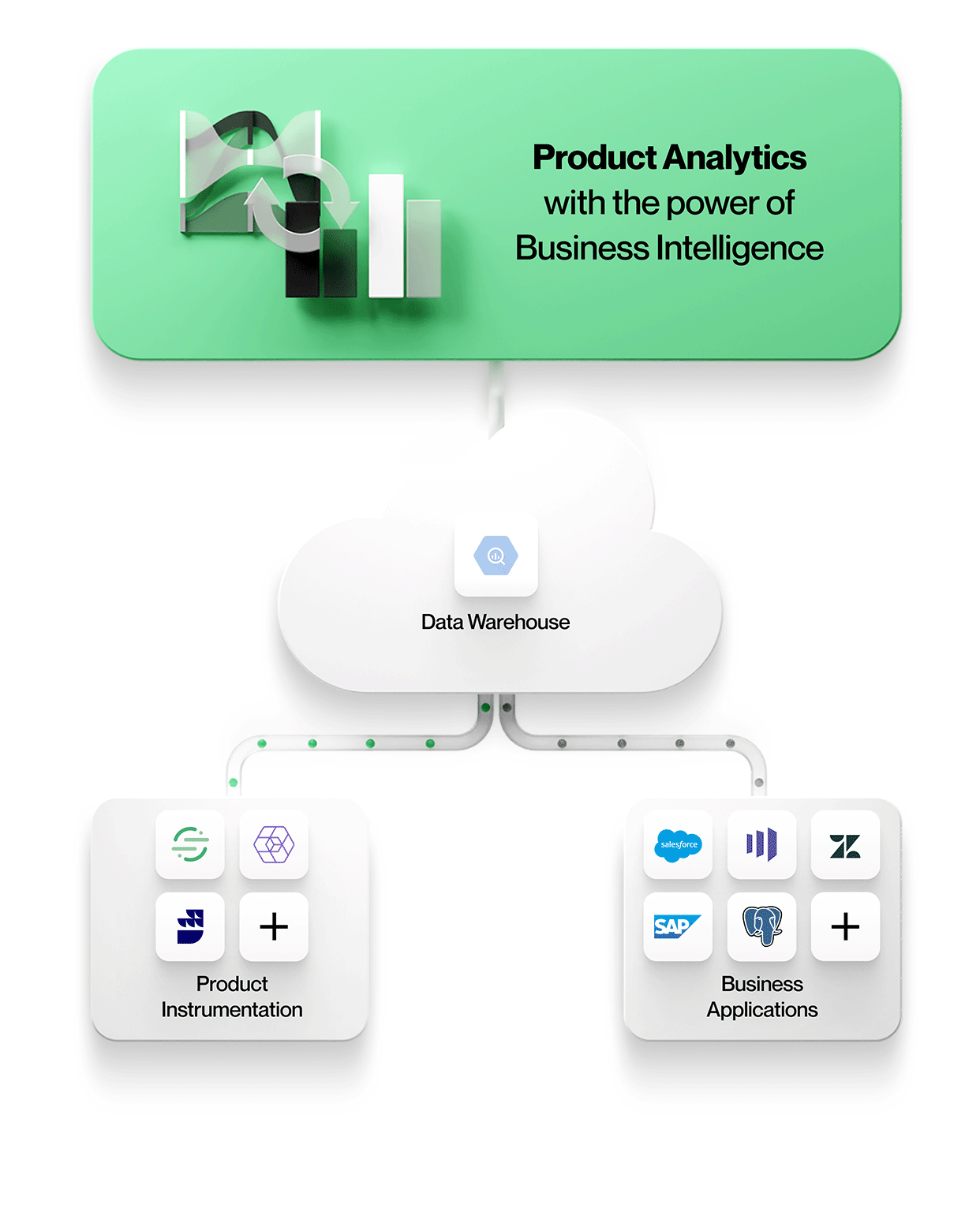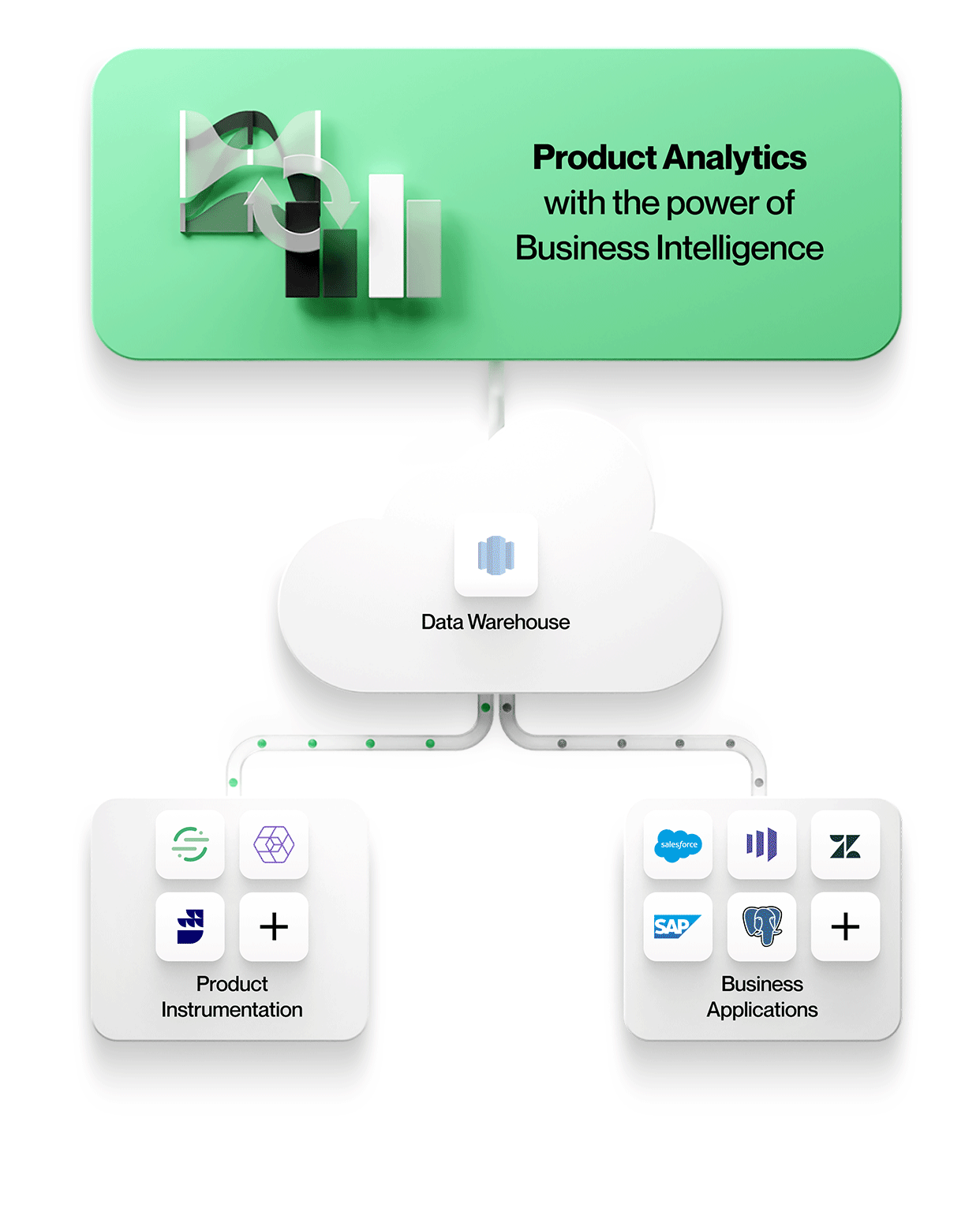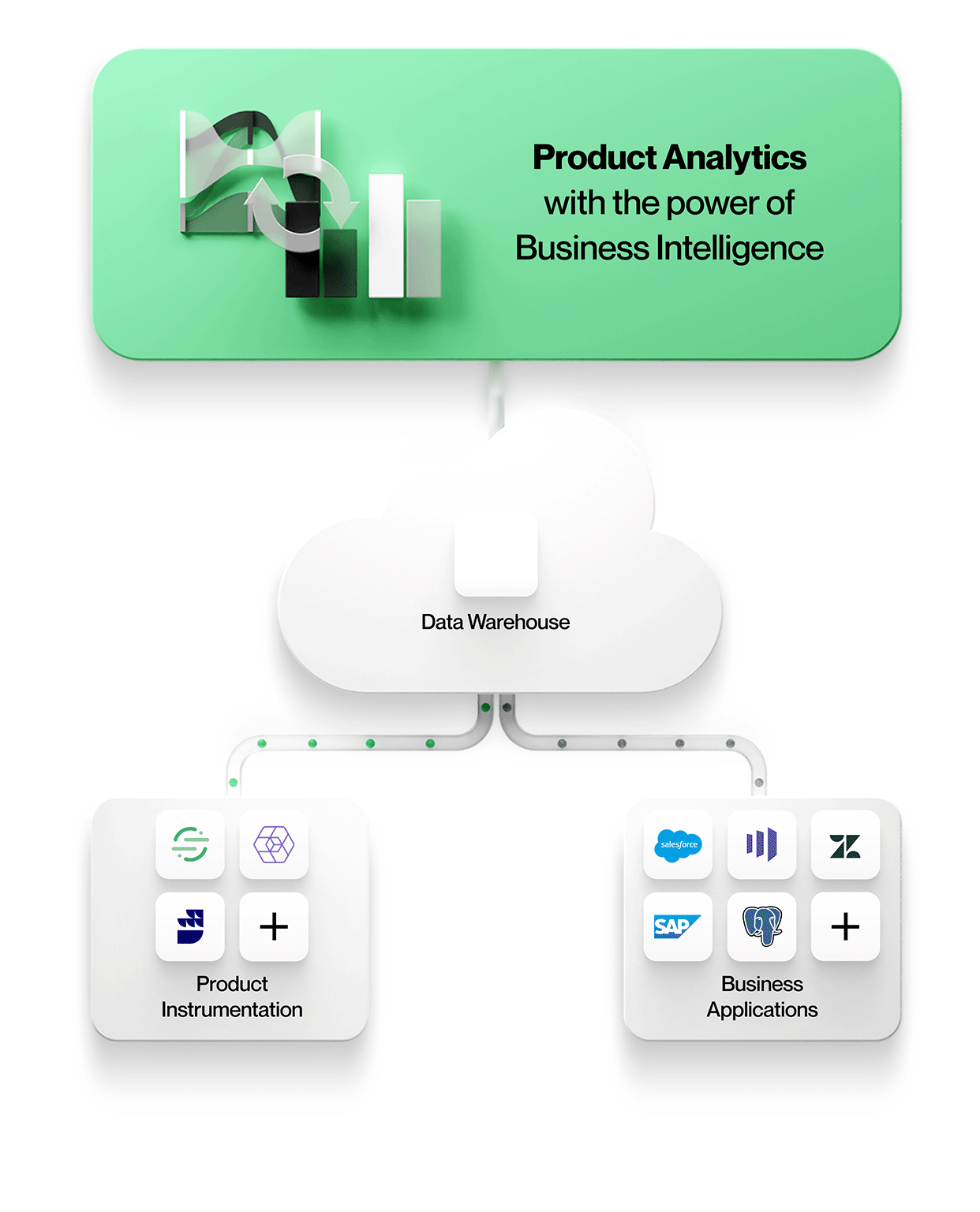
1. Product instrumentation data is stored with all other enterprise data
All the data, including product instrumentation, lands in the same central data lake or warehouse store. This simplifies manageability with one secure, governed store and avoids data silos.
2. Product instrumentation is decoupled from analytics
Product instrumentation is unopinionated. It does not dictate any particular data model, and it also does not force you into one particular tool for analytics.
Decoupled and unopinionated instrumentation allows you to model your unique business accurately, instead of forcing you to use a vendor-dictated data model. It also allows for the instrumented data to be usable by any analytics tool. Products such as Snowplow and RudderStack enable such decoupled instrumentation.
3. Product analytics tools work directly off data in the central data lake or warehouse enterprise store
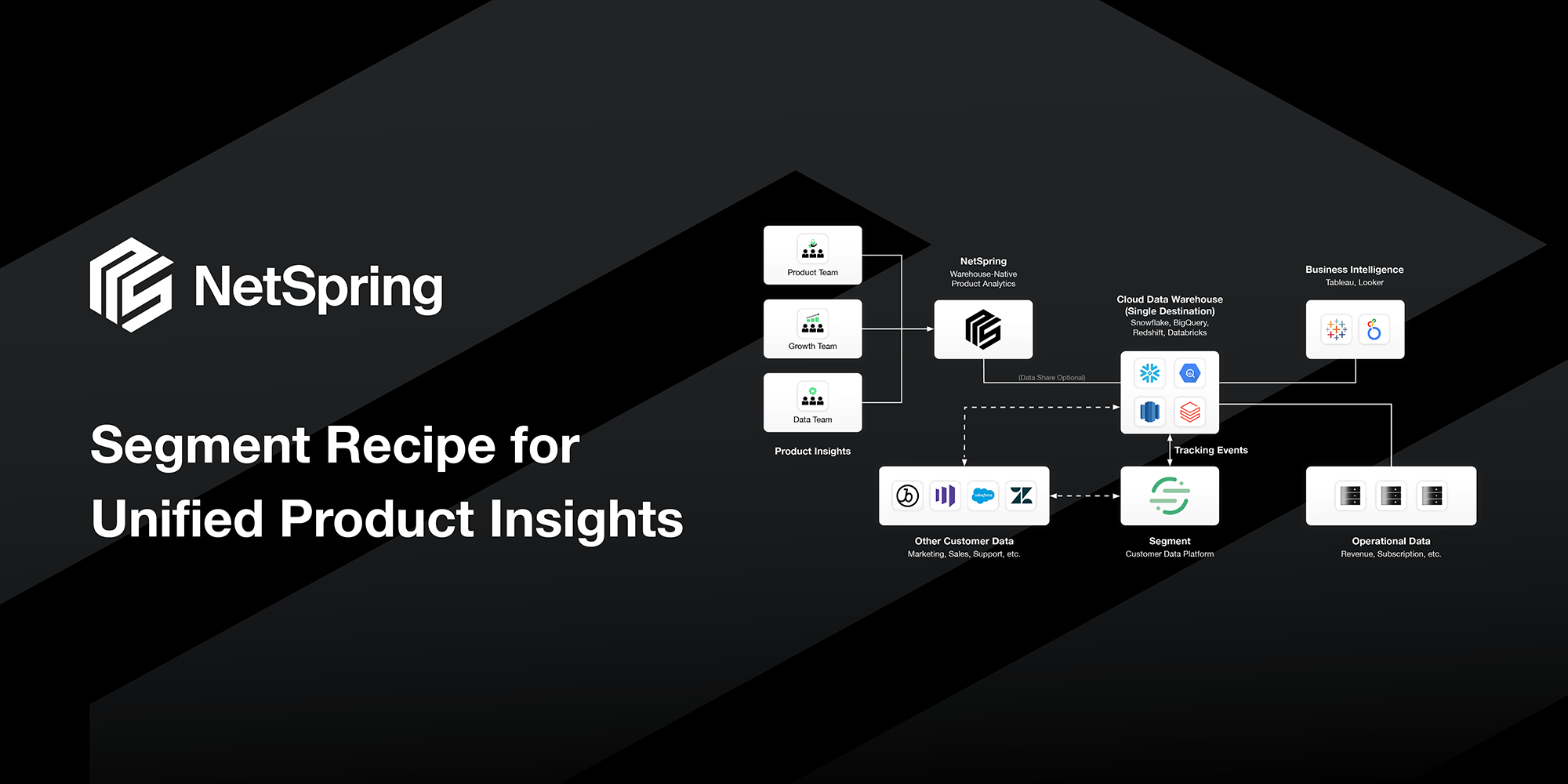
To enable context-rich product analytics, tools incorporate data from other business systems in their native form. This means working with entities and their relationships exactly as they appear in these business systems e.g. working with entities such as Accounts, Contracts, Revenue, and Leads from Salesforce; Tickets, SLAs, and Tasks from Zendesk; or Customers, Projects, and Tiers from NetSuite. Product analytics can be understood in context and correlated to business outcomes, making your analytics more valuable and relevant to everyone in the organization.
Product analytics data should also be transformed and queried in the same way as any other data: for example, using DBT to do data transformations or using SQL to query data with a relational model. This lets you make use of the expertise and tools already in use within your enterprise. It also allows any tool, such as an AI/ML tool or a custom application, to easily leverage that data.
Altogether, this modern architecture for product analytics results in lower TCO and higher business impact. Understanding your data with all its context is the future of product analytics.
Looking to add modern product analytics to your data stack?
NetSpring offers a next-generation product and behavioral analytics platform that is purpose-built for the modern data stack. Contact us to get a live demo.