Product analytics tools take the guesswork out of product development. They give teams “x-ray vision” into how users and cohorts are engaging with the product, as detailed as the click-through rate on a button or the dropoff in each step of a user journey.
Despite these benefits, many product management teams still haven’t adopted analytics tools, primarily because their legacy architecture is unable to address many real-world needs.
In this post, I’ll explain why product analytics should work directly on the modern data warehouse/data lakehouse, and how this solves many of the challenges and limitations for analytics today.
A Brief History of Product Analytics
Before full-fledged product analytics software there were web analytics tools such as Google Analytics, which provided aggregate statistics on website engagement, e.g. page views, session lengths, etc. Mixpanel and other first-generation product analytics tools then made a quantum leap by mapping the granular events comprising a user’s journey. Events include any way a user might interact with an app. Examples include clicking a sign-up button, completing a purchase, or browsing through a recommendations feed. Events give much deeper insight into user behavior than page views alone.
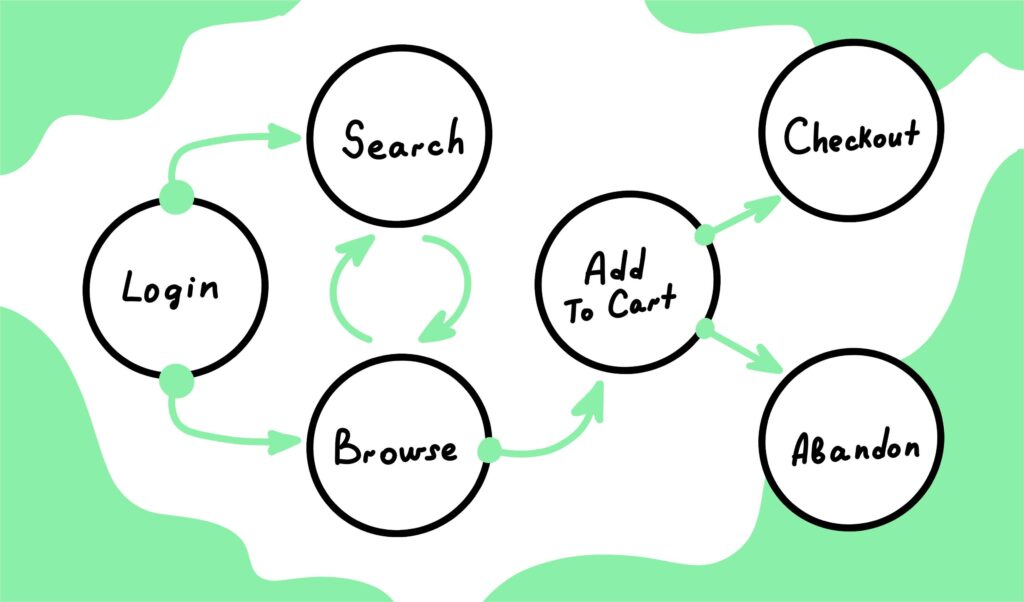
Early product analytics tools also expanded the reach of tracking beyond the web to cover other digital touchpoints such as mobile and email. Together, these changes radically improved development teams’ ability to identify engagement drivers and grow their products. Every UX decision could be fully thought through and justified with data. Today, the adoption of analytics tools is high, although there still are frictions holding many teams back from making the shift.
Why Product Analytics Belongs on the Data Warehouse
Since the advent of product analytics, the importance of event data hasn’t changed—it’s only become more essential. But one thing has changed, which is how businesses work with and manage their data.
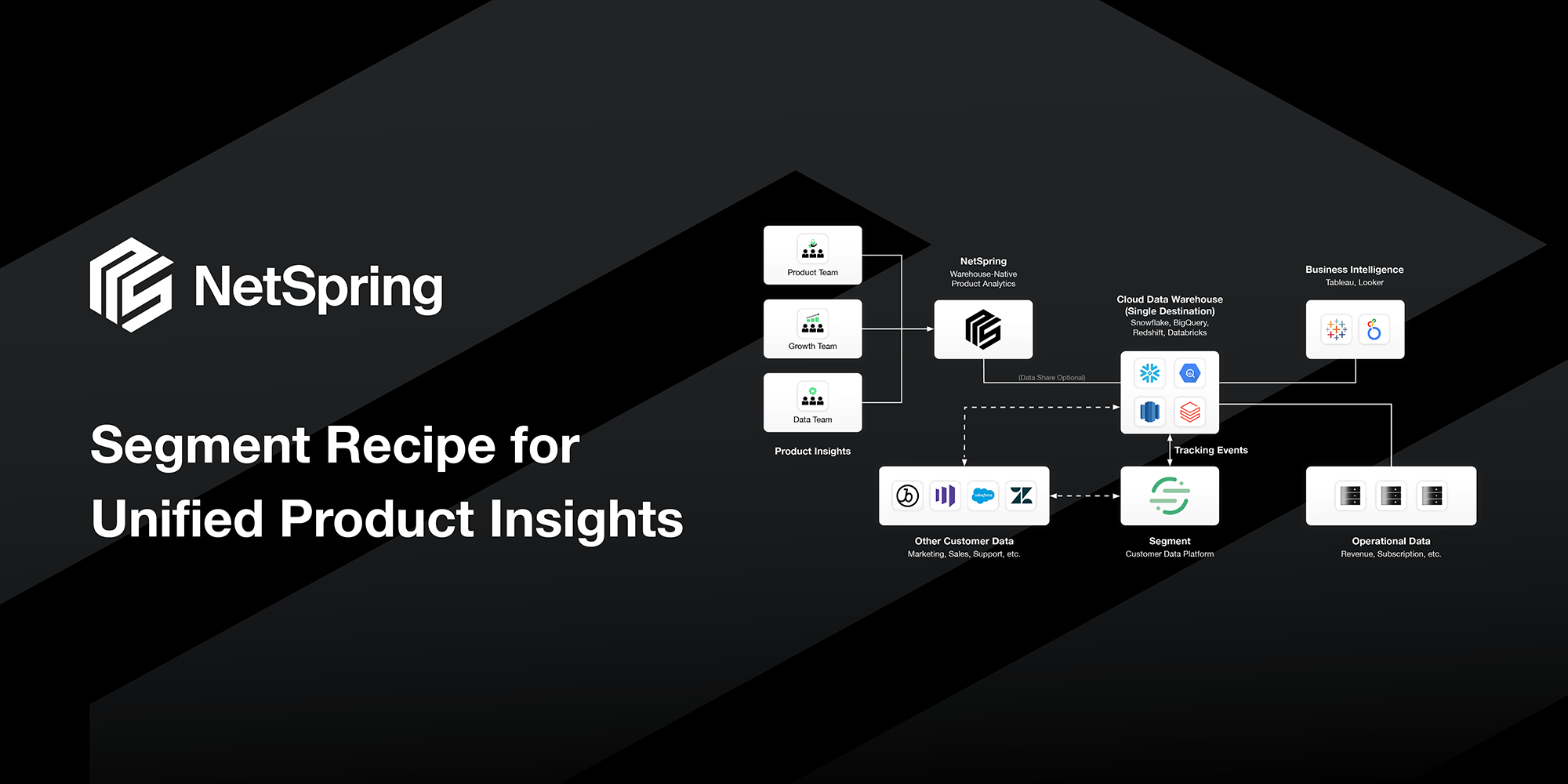
Businesses today need product analytics that works directly on the data warehouse.
Here are three reasons why:
1. Avoid Data Duplication and ETL Pipelines
Many first-generation analytics tools evolved organically to ingest product usage data into their internal storage. These are proprietary datastores that often require building ETL (extract, transform, load) pipelines to bridge across data silos. A proliferation of ad hoc data pipelines is highly expensive for data engineers to maintain, while failing to solve the core business need around retaining control of where data is stored.
Next-generation analytics tools directly tackle these problems by leveraging a company’s data warehouse as a composable CDP, a modularized version of a customer datastore with software layers that an organization can customize. A business can keep all its data in one place and the analytics tool interfaces with that datastore, avoiding unnecessary duplication. This means no more data silos and reduced costs for the data engineering team.
2. Eliminate Tunnel Vision
Product analytics has its origin in analyzing a clickstream and most first-generation tools still restrict users to a single event stream. In contrast, understanding user behavior may require analyzing additional interactions such as from backend databases or third-party SaaS tools (e.g. user churn by spend in Salesforce). Existing tools make this common need overly difficult, leaving users vulnerable to tunnel vision – having visibility only into a narrow sliver of user experience.
A data warehouse is the natural repository for all of a company’s data, including product instrumentation data from digital touchpoints, transactions from the application database, third-party SaaS data such as customer support tickets, etc. Leveraging a data warehouse enables product teams to apply the complete context of a user’s experience to product analytics resulting in high-quality, broad insights instead of tunnel vision from traditional analytics architectures.
3. Provide Greater Extensibility
First-generation product analytics tools support a fixed set of queries out of the box. When a team needs to answer a new question, it’s typical to fall back to a separate business intelligence (BI) tool or Python notebook, sidestepping product analytics altogether while introducing modeling overhead and consistency issues. Iterating on queries becomes a very time-consuming and manual process.
Product analytics layered on data warehousing can go further in supporting advanced or ad hoc analytical needs, postponing or eliminating the need to replicate the analytics in a BI tool. The data warehouse approach is extremely scalable to an organization’s needs and can handle a range of use cases and levels of complexity. There is more depth to this claim than can fit here, but stay tuned for future updates from our team on this topic.
Wrapping up
First-generation product analytics has poor ROI because it works on a legacy data stack that offers limited analytical capabilities.
The emergence of the cloud data warehouse as a mature general-purpose platform unlocks a wide range of possibilities for product analytics.
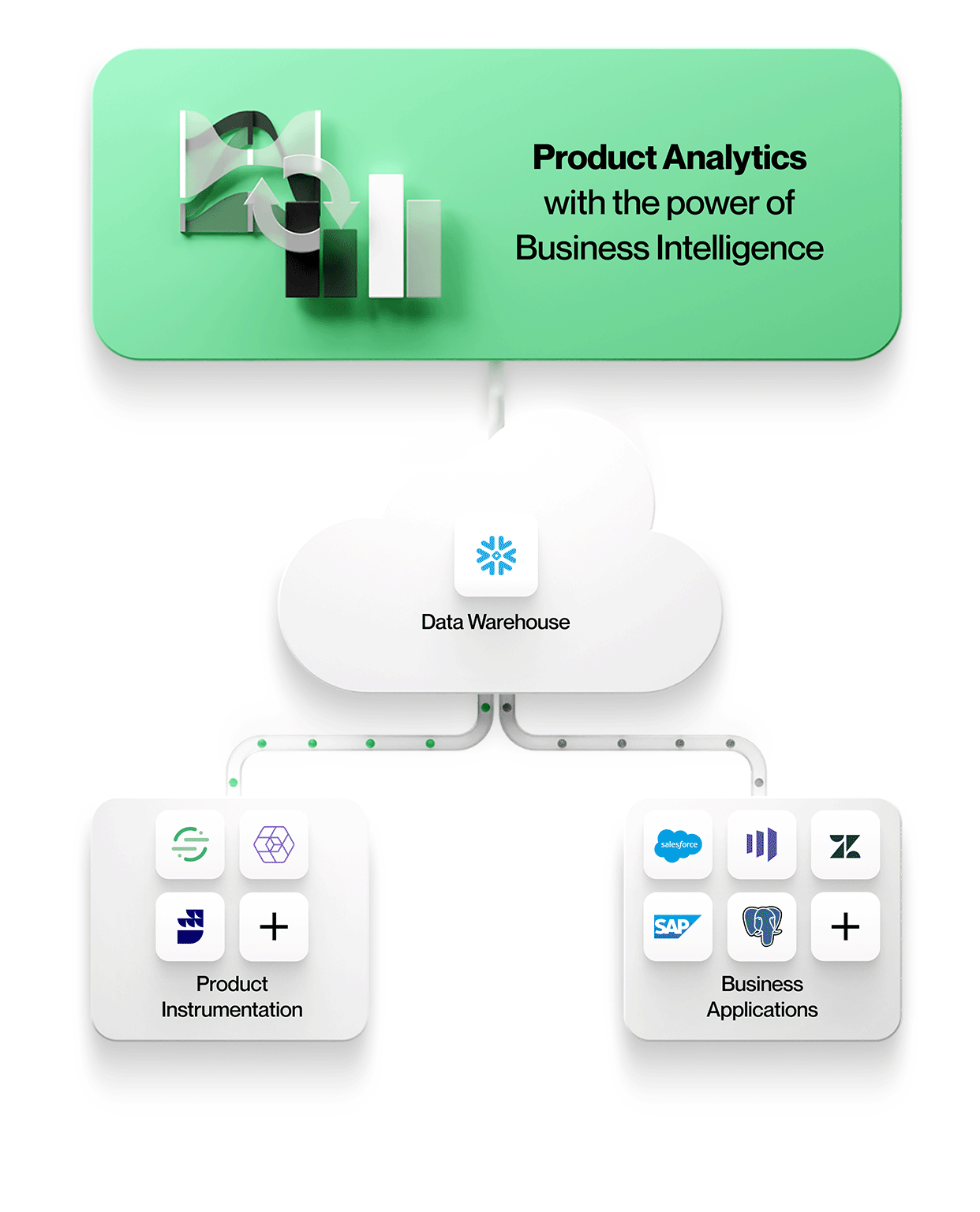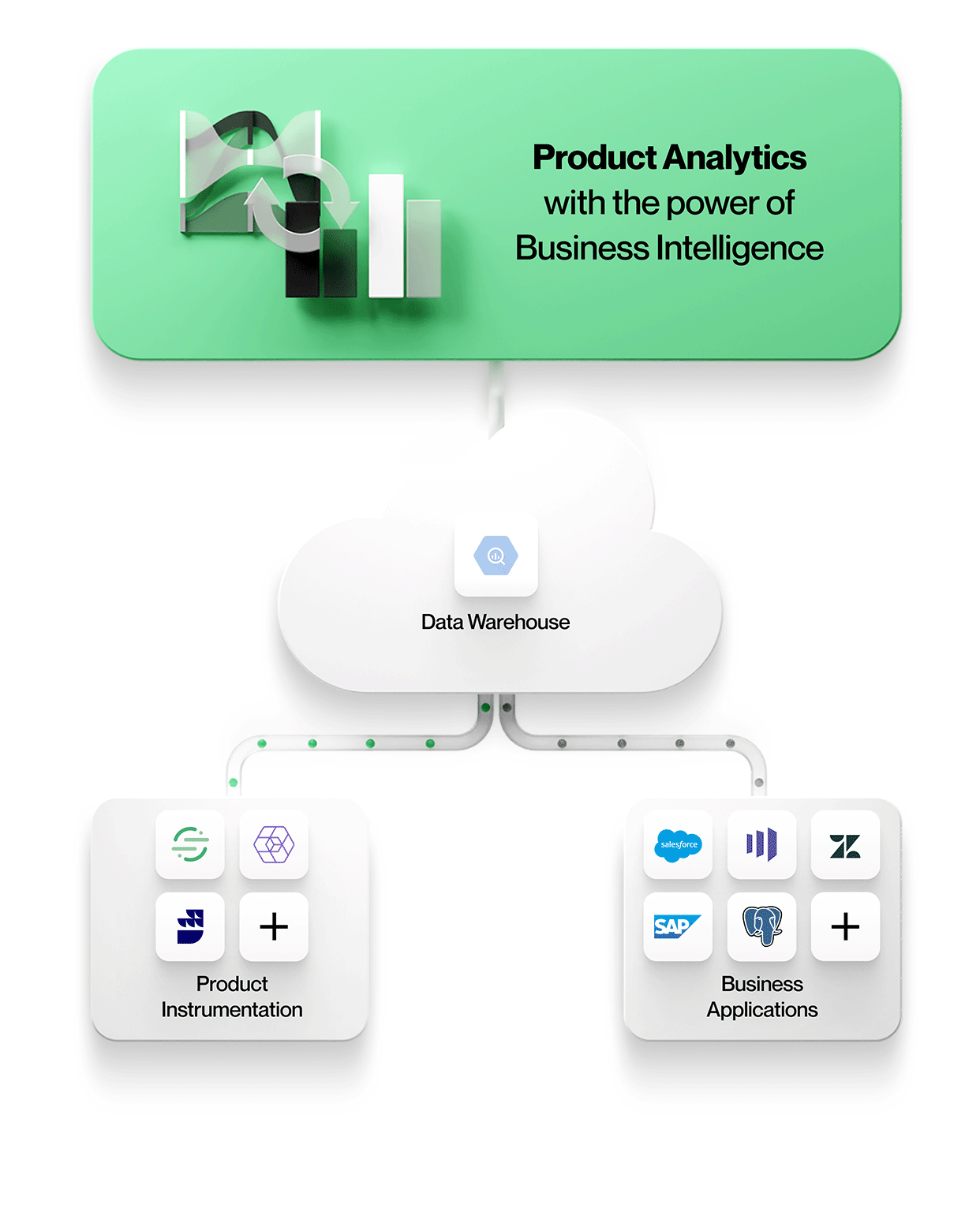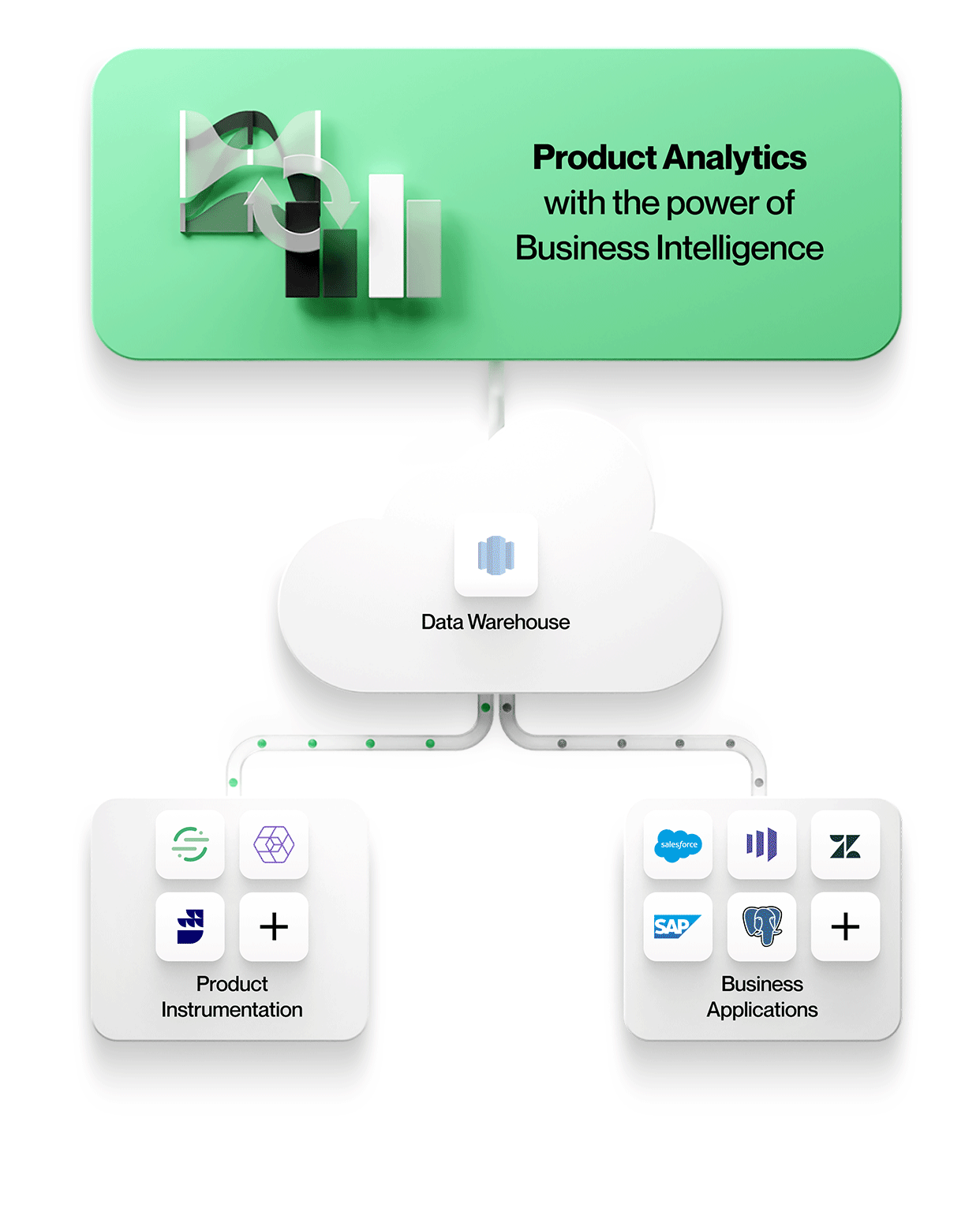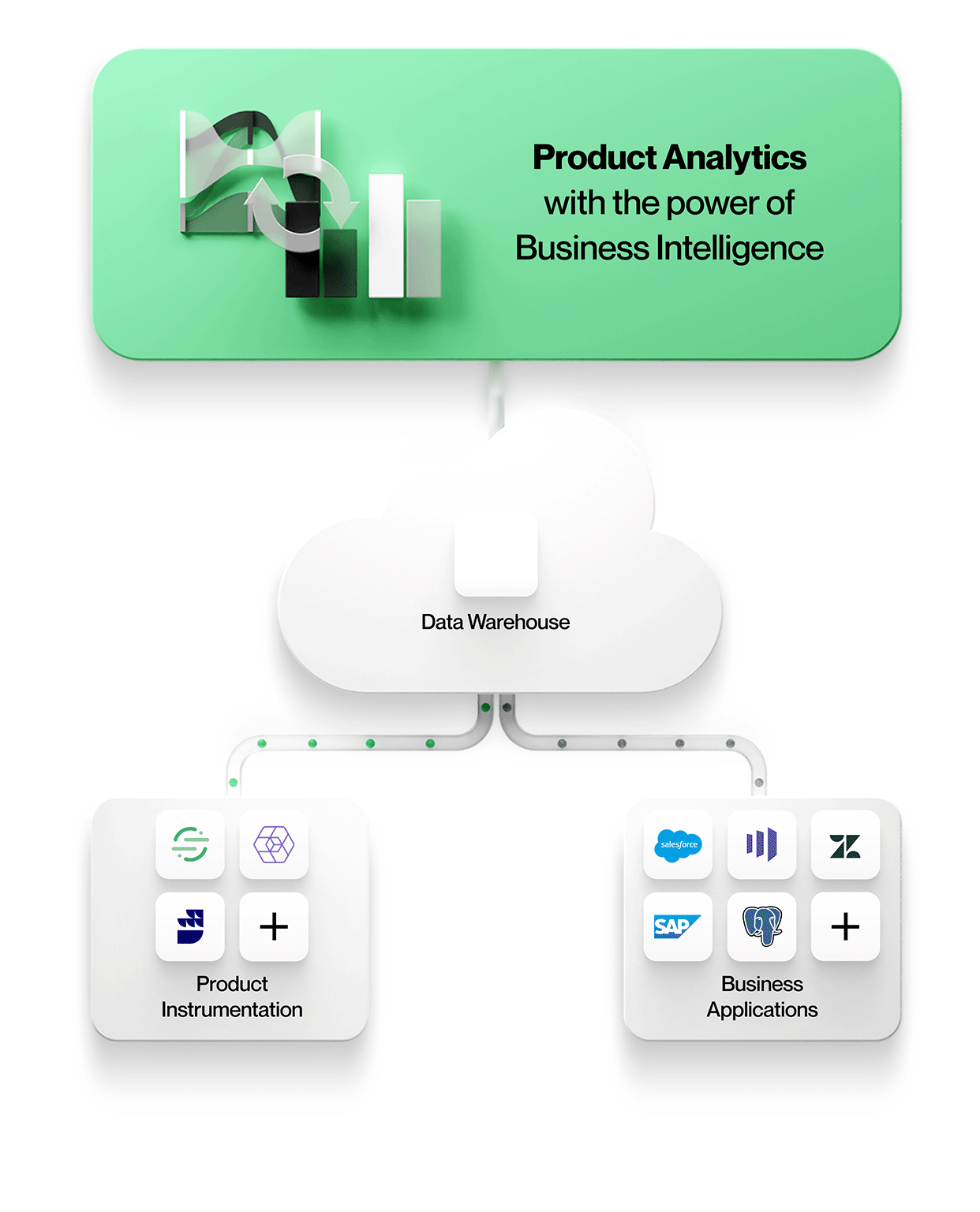 At NetSpring, our vision is to build a product analytics experience that works directly on the data warehouse and scales far beyond the use cases of today. Contact us to get a live demo.
At NetSpring, our vision is to build a product analytics experience that works directly on the data warehouse and scales far beyond the use cases of today. Contact us to get a live demo.
Recommended Reading:
- (Oracle)
- (Mixpanel)
- (Snowflake)
- (Databricks)