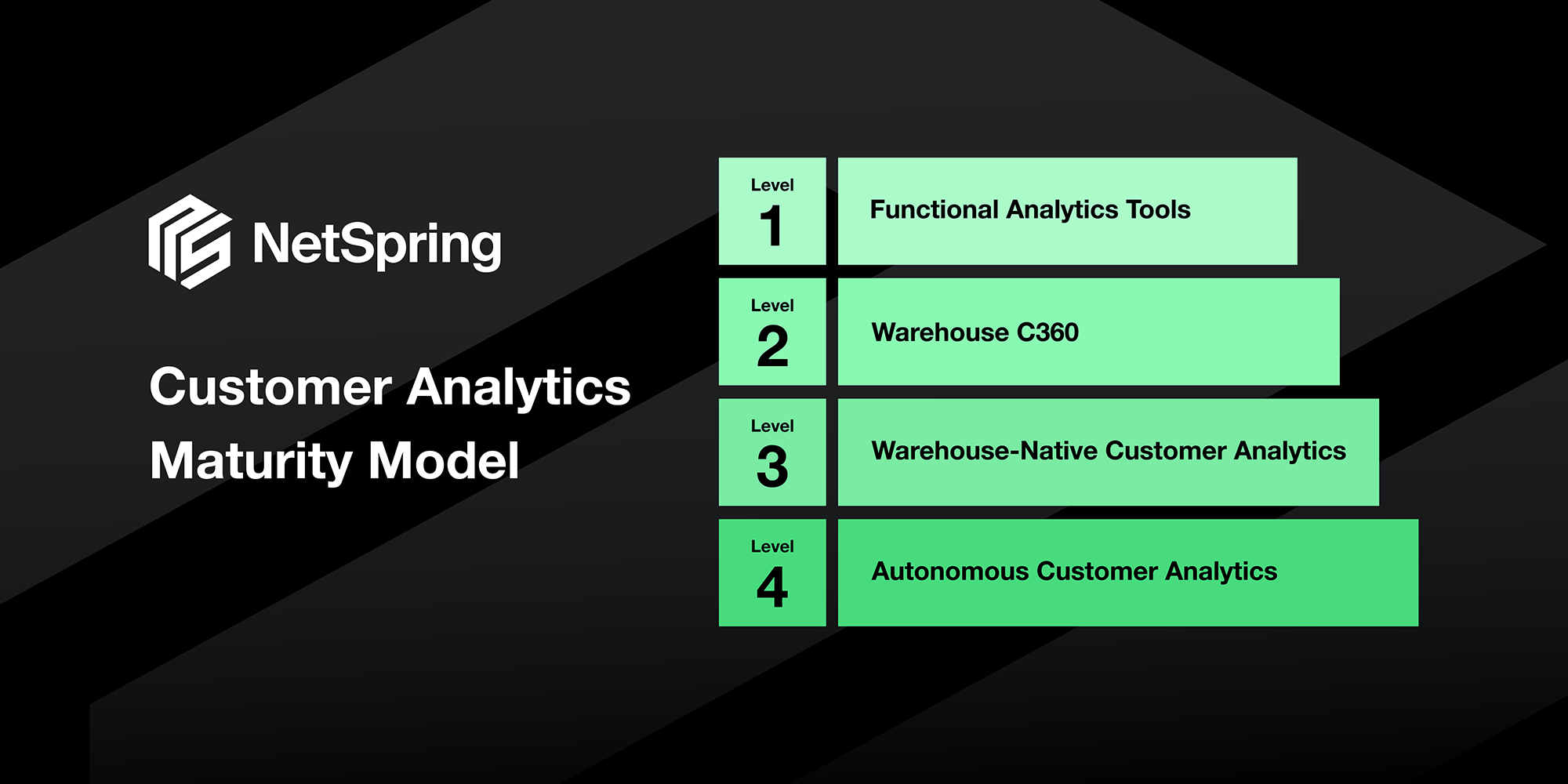
The next generation of product analytics has emerged with the Modern Data Stack. It is uniquely architected on top of a centralized cloud data store for all data, and offers significant advantages in terms of cost and analytical sophistication.
In a previous blog, Vijay Ganesan looked at both first generation and the next generation of product analytics, and explored how product analytics must evolve to fit into the Modern Data Stack. In this blog we’ll highlight the differences between a modern warehouse-native approach versus an evolutionary workaround from first-generation tools that leads to data being imported or exported out of the warehouse.
Warehouse-Native Product Analytics
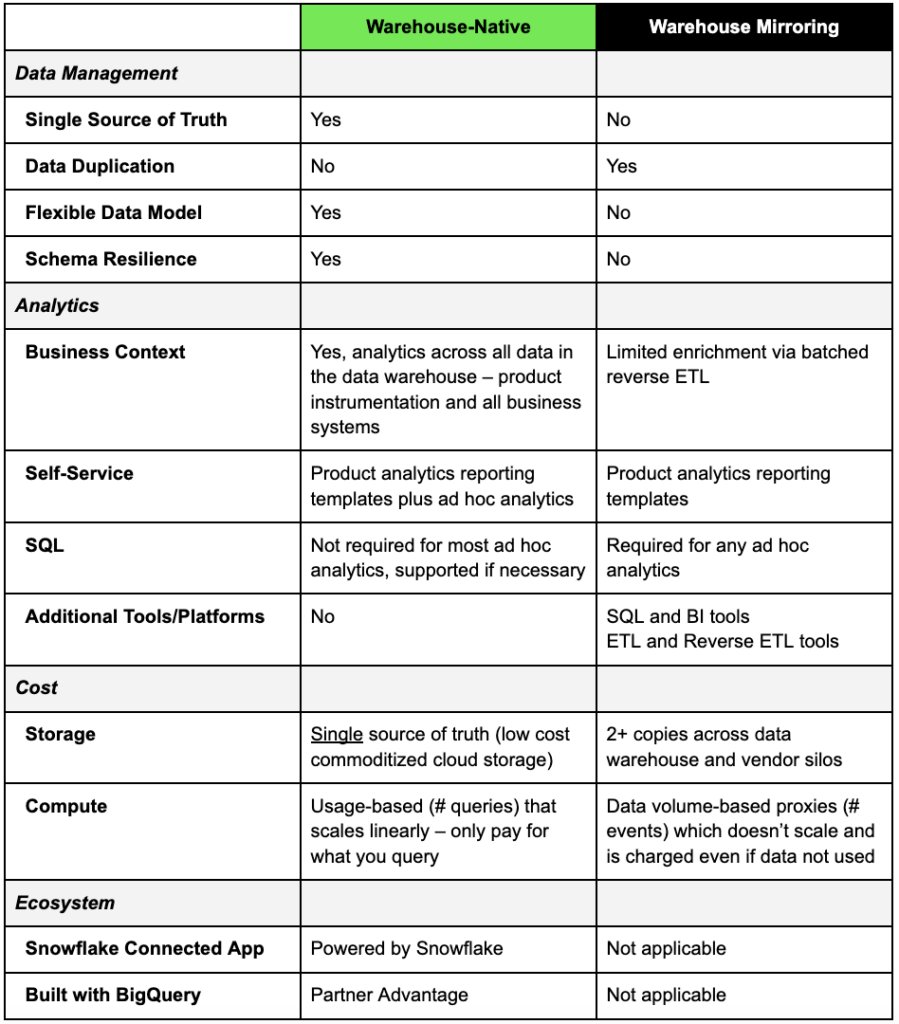
Warehouse-native product analytics solutions like NetSpring leverage a single source of truth for consistent and trustworthy insights. They can directly query both event-oriented usage and relational reference data in the data warehouse, to access all relevant customer and behavioral data – with no data duplication. NetSpring for instance, works natively off all mainstream cloud data warehouses, including Snowflake®, Google BigQuery™, Redshift, and Databricks, to offer self-service product analytics and the exploratory power of BI for ad hoc visual data exploration.
Product Analytics via Warehouse Mirroring
In contrast, popular first-generation solutions such as Amplitude and Mixpanel, pre-date the Modern Data Stack and have proprietary data stores. This siloed approach forces many enterprises to mirror or reverse ETL select customer or business data from the data warehouse back for limited enrichment. With data being duplicated across analytics platforms, the results from first-generation tools are generally inconsistent with analytics run directly on the data warehouse.
The limitations of purpose-built, pre-canned product analytics reports forces many others to export instrumentation data to the data warehouse. With relevant customer and behavioral data (e.g. spend, support, social, etc.) enriched with product usage data, deeper analysis is done via general-purpose SQL and BI tools, like Mode and Looker. These data exports again result in multiple copies of the same data, and introduces additional analytics tools that were never designed to handle event-oriented data or support self-service product analytics.
Warehouse-Native vs. Warehouse Mirroring
When first-generation vendors tout their warehouse capabilities, they are referring to an export to your existing data warehouse and/or reverse ETL from the warehouse back into their silo. In some cases, vendors may even be referring to duplication from your data warehouse, to yet another data store, their own! In short, those exports result in 2 or more copies of the same product usage data!
Conclusion
The emergence of the cloud data warehouse as a mature general-purpose platform unlocks a wide range of possibilities for product analytics.
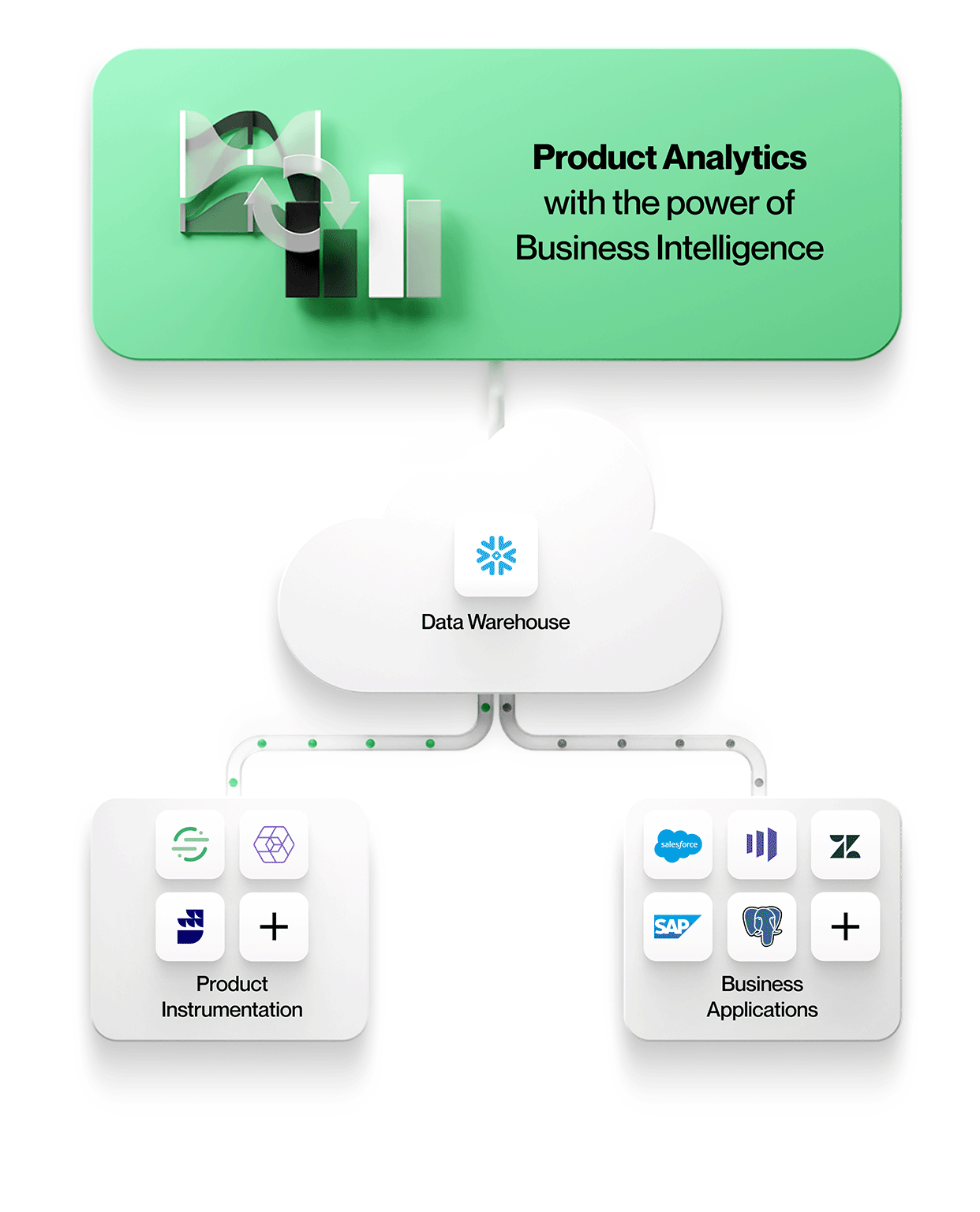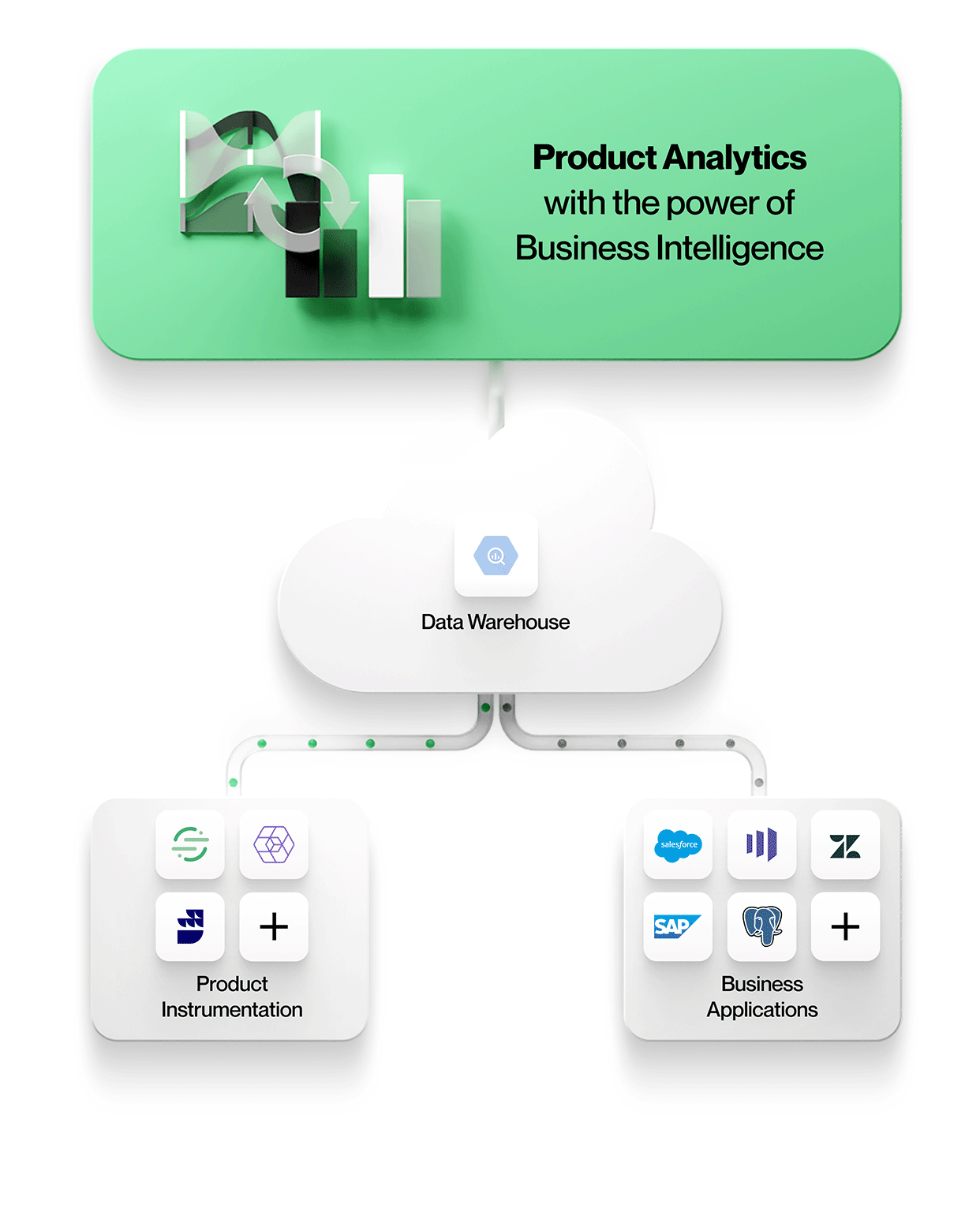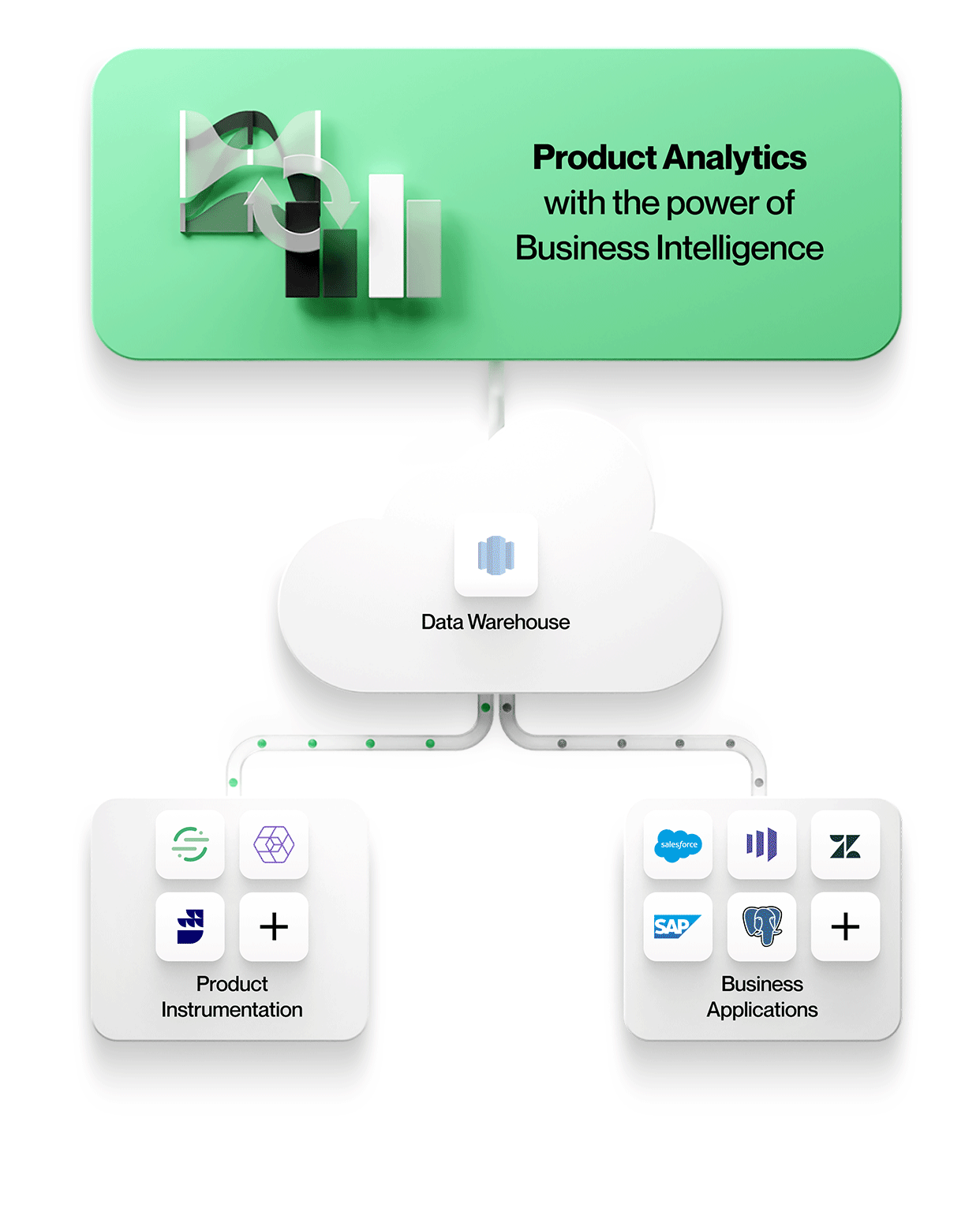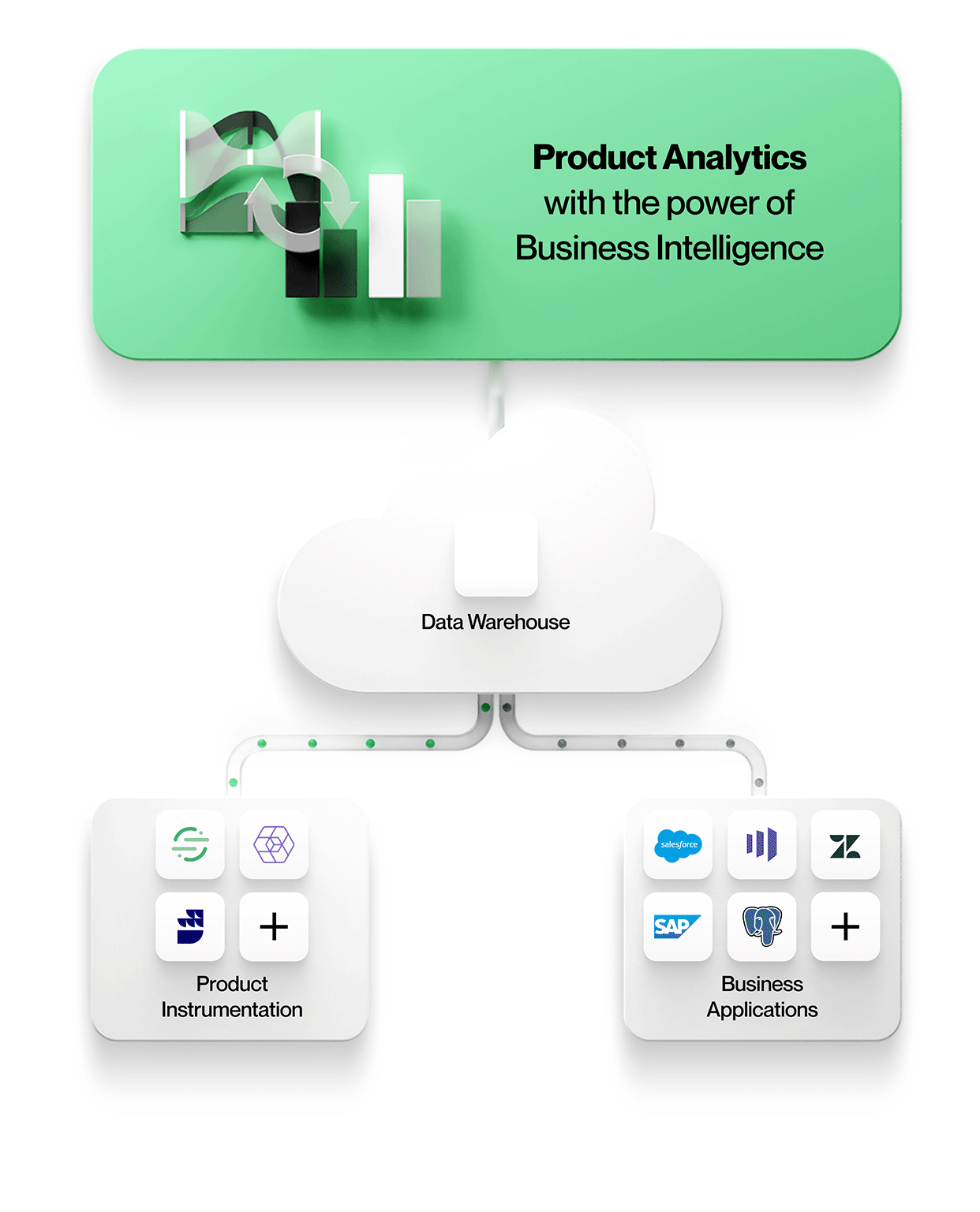
First, data silos can be avoided when product usage data is stored with all other enterprise data in one secure, governed store. There it can be accessed by any analytics tool, whether it be optimized for event-oriented data, relational data, or ideally, both event and relational data for context-rich product analytics on data in their native form.
This means working with entities and their relationships exactly as they appear in business applications e.g. accounts, contracts, revenue, and leads from Salesforce, or tickets, SLAs, and tasks from Zendesk. Product analytics can be understood in context and correlated to business outcomes, making your analytics more valuable and relevant to everyone in the organization.
Altogether, this modern architecture for product analytics results in massive savings in terms of storage and compute, and higher business impact from more sophisticated, ad hoc analytics. NetSpring offers this next generation of product analytics at a fraction of the cost of traditional approaches, with self-service product analytics and the exploratory power of BI, by working natively on top of your data warehouse. Contact us today to get a live demo.